Frontier Research Overview

[Cognition refers to] “the mental action or process of acquiring knowledge and understanding through thought, experience, and the senses.”
Lexico. Oxford University Press and Dictionary.com.

Cognitive Ability enable robots to work in uncontrolled environments and alongside humans.
We study and design cognitive systems that enable a robot to behave robustly in a variety of tasks and environments. The research topics include (i) Meta-learning, (ii) Collaborative agents, (iii) Representation and Reasoning, (iv) Reinforcement Learning, and (v) Explainable AI (XAI).
Research Highlights
2025
Improving Locomotion Learning Efficiency of CPG-RBF Networks under Morphological Damage with Multiple Value Functions
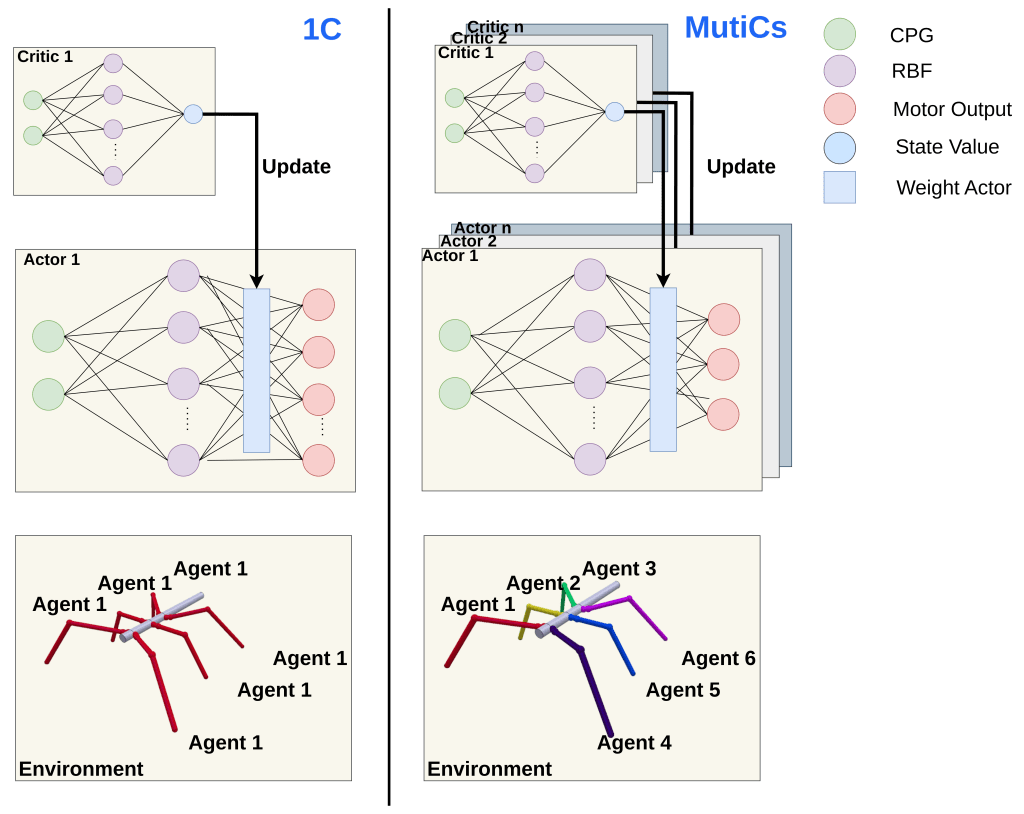
In this work investigates a data-driven locomotion framework that integrates reinforcement learning (RL) with biologically inspired central pattern generators (CPGs) for legged robots. CPGs provide stable rhythmic motion, while RL modulates CPG parameters to enable rapid adaptation to environmental changes and morphological variations. By employing CPG–RBF networks and multiple value functions, the framework aims to improve learning efficiency and robustness compared to conventional single-critic approaches, particularly in multi-agent or decentralized control settings. Although evaluated in generic legged robotic platforms, the proposed method is broadly applicable to bio-inspired systems requiring adaptive and resilient locomotion
2023
We study the problem of creating agents that can cooperate with other agents even though they have not been trained with each others before. We found that better diversification in the trianing can give the agent a better generalisation ability [1]. We also found that the cooperative skill could be learn via meta-reinforcement learning [2].
Generating Diverse Cooperative Agents by Learning Incompatible Policies [4]
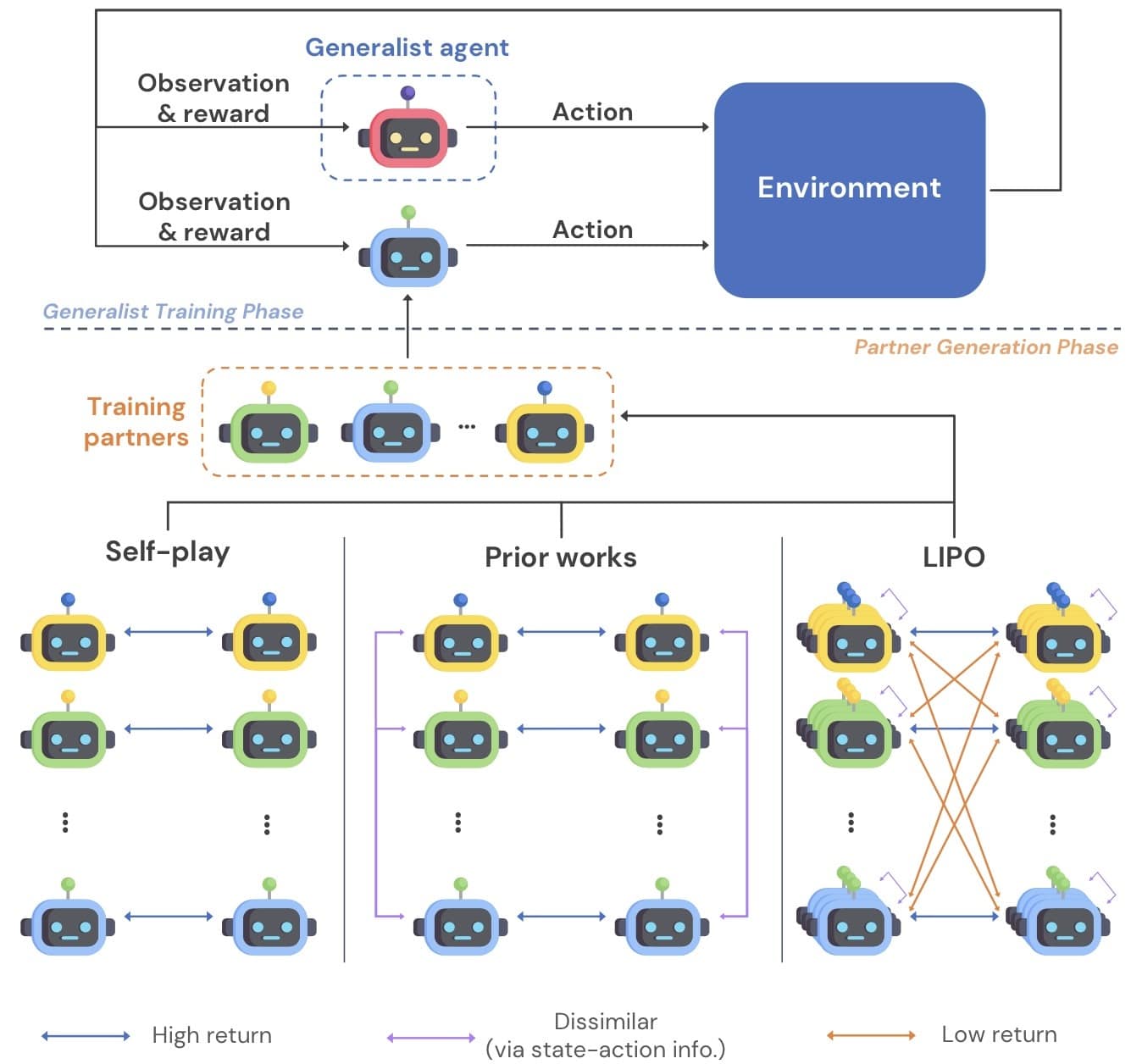
In this work, we propose to learn diverse behaviors via policy compatibility. Conceptually, policy compatibility measures whether policies of interest can coordinate effectively. We theoretically show that incompatible policies are not similar. Thus, policy compatibility—which has been used exclusively as a measure of robustness—can be used as a proxy for learning diverse behaviors. Then, we incorporate the proposed objective into a population-based training scheme to allow concurrent training of multiple agents. Additionally, we use state-action information to induce local variations of each policy. Empirically, the proposed method consistently discovers more solutions than baseline methods across various multi-goal cooperative environments. In multi-recipe Overcooked, we show that our method produces populations of behaviorally diverse agents, which enables generalist agents trained with such a population to be more robust. Finally, in high-dimensional complex SMAC environments, LIPO learns diverse winning strategies.
2021
NeuroVis: Real-Time Neural Information Measurement and Visualization of Embodied Neural Systems [3]
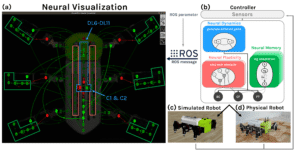
We propose for the first time a tool “NeuroVis” to read a robot brain and to see what the robot thinks. NeuroVis is real-time neural spatial-temporal information measurement and visualization. It can measure temporal neural activities and their propagation throughout the network. By using this neural information along with the connection strength and plasticity, NeuroVis can visualize neural structure (NS), neural dynamics (ND), neural plasticity (NP), and neural memory (NM). We have demonstrated the use of NeuroVis to analyze and visualize “robot brain” during behaving. NeuroVis will offer the opportunity to better understand embodied dynamic neural information processes, boost efficient neural technology development, and enhance user trust. It can be used as a tool for explainable AI and cognitive robotics research.
Learning to Cooperate with Unseen Agents Through Meta-Reinforcement Learning [2]
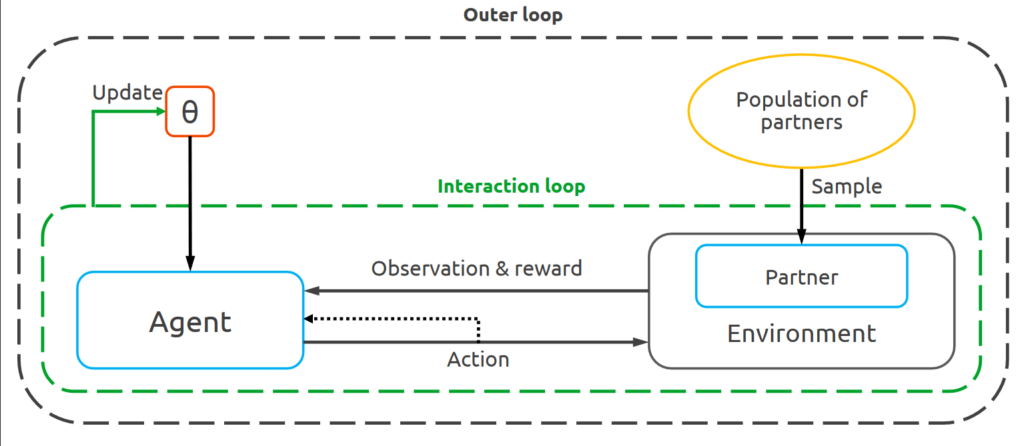
Ad hoc teamwork problem describes situations where an agent has to cooperate with previously unseen agents to achieve a common goal. For an agent to be successful in these scenarios, it has to have cooperative skills. One could implement cooperative skills into an agent by using domain knowledge (e.g., goals, roles, and protocols) to design the agent’s behaviours. However, in complex domains, domain knowledge might not be available. Therefore, it is interesting to explore how to directly learn cooperative skills from data. In this work, we apply meta-reinforcement learning (meta-RL) formulation in the context of ad hoc teamwork problem. Our experiments show that such a method could produce cooperative agents in two cooperative environments with different cooperative circumstances.
2020
Investigating Partner Diversification Methods in Cooperative Multi-agent Deep Reinforcement Learning [1]

Overfitting to learning partners is a known problem, in multi-agent reinforcement learning (MARL), due to the co-evolution of learning agents. Previous works explicitly add diversity to learning partners for mitigating this problem. However, since there are many approaches for introducing diversity, it is not clear which one should be used under what circumstances. In this work, we clarify the situation and reveal that widely used methods such as partner sampling and population-based training are unreliable at introducing diversity under fully cooperative multi-agent Markov decision process. We find that generating pre-trained partners is a simple yet effective procedure to achieve diversity. Finally, we highlight the impact of diversified learning partners on the generalization of learning agents using cross-play and ad-hoc team performance as evaluation metrics.
\
For more details, see :
[1] Charakorn et al., ICONIP 2020. Communications in Computer and Information Science, 2020 (presentation video, pdf)
[2] Charakorn et al., AAMAS 2021. The 20th International Conference on Autonomous Agents and Multiagent Systems.(poster, full paper)
[4] Charakorn, R., Manoonpong, P., Dilokthanakul, N. (2023) Generating Diverse Cooperative Agents by Learning Incompatible Policies, The Eleventh International Conference on Learning Representations (ICLR, A* conf.)